
Chapter 1: Reinforcement Learning for LLMs in 2025 — A Mathematical and Practical Series

A multi-part deep dive into how RL algorithms like PPO, GRPO, DAPO, and GSPO redefined reasoning in Large Language Models
Chapter 1: What is Reinforcement Learning? What is all the fuss about?
Introduction
Reinforcement Learning (RL) has rapidly evolved from a niche academic subfield into the bedrock of modern Large Language Model (LLM) fine-tuning. By 2024, the world's most powerful Large Language Models - like GPT 4 and Claude Sonnet - were great linguistic acrobats, capable of generating fluent and coherent responses across diverse contexts. And yet, they remained clumsy thinkers. These models could write passable poetry, mimic human dialogue, but constantly stumbled on tasks demanding structured reasoning and long-horizon planning.
This shortcoming became painfully obvious on challenging benchmarks like MMMU, AIME, and SWEBench. Despite strong fluency, they lacked structured reasoning, a limitation that reinforcement learning was uniquely suited to address.
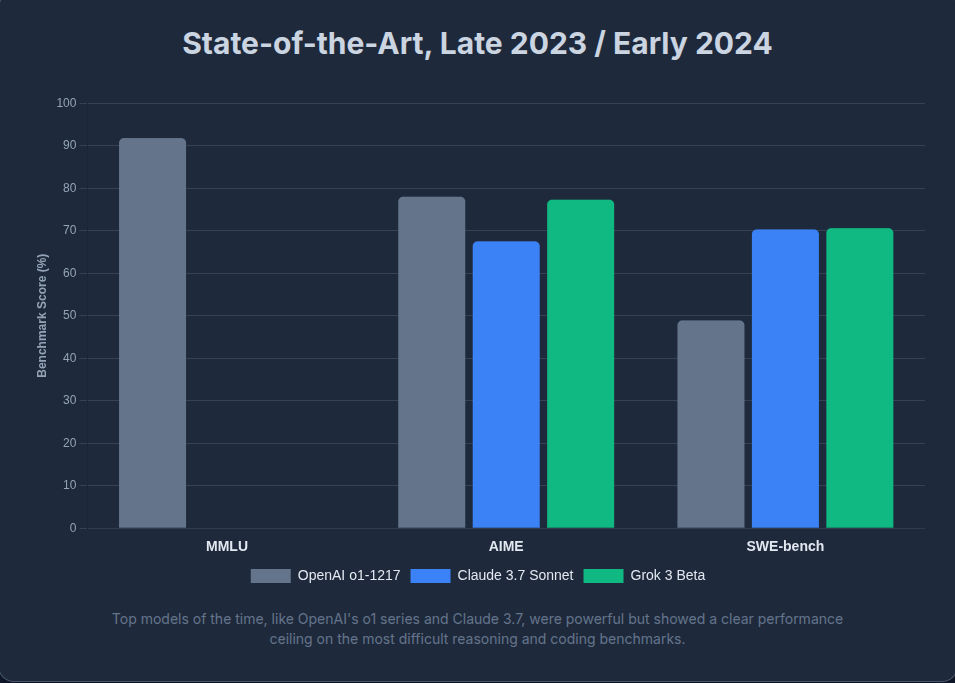
The tide began to turn with OpenAI’s O1 - one of the first public glimpses into what RL-backed training could achieve. While the training details behind O1 remain obscure, it sparked public interest into what was earlier a niche academic field. Soon after, models like DeepSeek-R1 emerged - not just competitive, but in some cases surpassing the best proprietary systems. A closer look into these models revealed that they had been trained using Reinforcement Learning.
Much of this leap can be traced back to the advances in RL algorithms themselves. Techniques like Proximal Policy Optimization (PPO) - which laid the groundwork. But newer variants like GRPO, DAPO and GSPO (Don’t worry about these terms for now - we will learn about them as we progress into the series) - introduced greater sample efficiency, scalability and robustness.
By 2025, a clear consensus between academia and industry had emerged - that Reinforcement learning is a crucial foundation to enable machines to “think”.
What This Series Is About:
But let’s face it: RL can be intimidating. The math is heavy. The terminology-dense. And when applied to LLMs, the entire thing feels rather overwhelming.
So here’s our goal:
We’re going to de-mystify reinforcement learning for LLMs, one algorithm at a time.
This is Part 1 of a multi-part series. In this post, we’ll start from the very beginning: what is RL, really? Who are the main characters in this story - agents, environments, policies, rewards? How does a “trajectory” differ from a single example? And why does all this matter so much in the age of trillion-parameter models?
Then, in the next chapters, we’ll zoom into the actual algorithms that power this revolution:
- Part 2: We’ll distinguish between value-based and policy-based RL- two philosophies with very different trade-offs.
- Part 3: We’ll begin our deep dive into Proximal Policy Optimization (PPO) - the workhorse behind today’s best LLMs.
- Part 4 and beyond: We’ll walk through advanced variants like GRPO, DAPO, and GSPO, slowly increasing the rigour as we progress.
Our style will be mathematically honest, but always mindful of clarity. No skipping steps. No black-box claims. And most importantly, no assuming you already know RL.
By the end of this series, our hope is simple: you’ll not only understand what these RL algorithms do - you’ll also deeply grasp why they were needed, how they evolved, what's coming next and most importantly, they make you interested in reinforcement learning
What is Reinforcement Learning?
Imagine you’re playing Minesweeper. Each tile you click might be a safe space, or a mine. You don’t know in advance where the mines might be, but over time you learn that certain patterns (like “1” adjacent to an unrevealed tile) signals danger. Each move you make gives you feedback: safe clicks keep the game going, while clicking on mines reset your progress. What you’re doing, whether you realise it or not, is reinforcement learning.
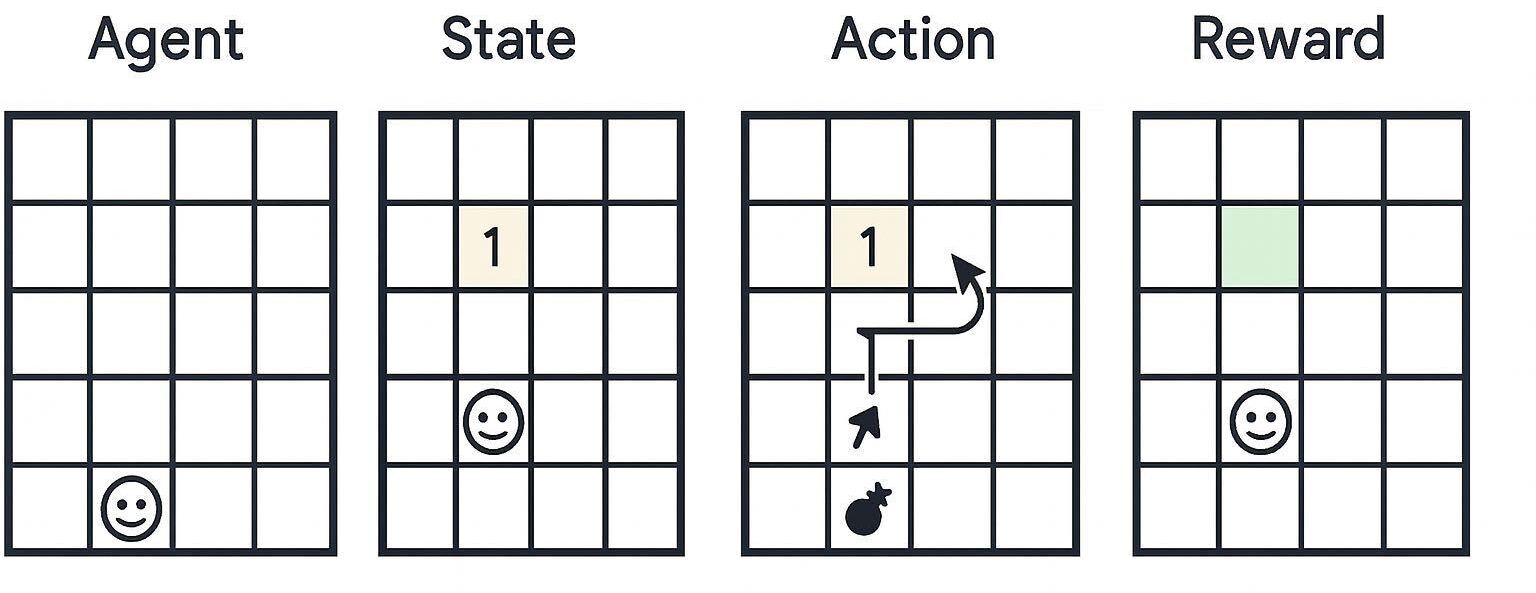
At its core, Reinforcement Learning (RL) is the science of learning by trial and error, guided by rewards and penalties. Unlike supervised learning - where a model learns from labelled examples - RL is about an agent learning to act in an environment to maximise some notion of cumulative reward over time.
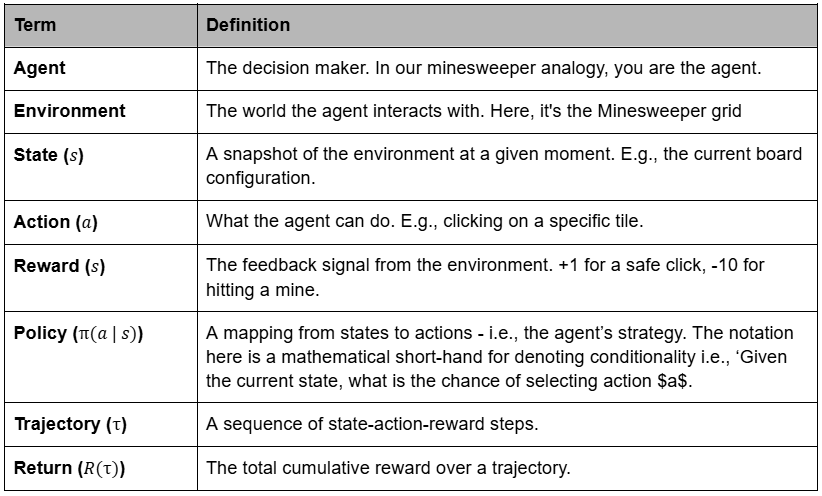
Let’s formally define key components that you’d see in any RL paper, or a blog.
The Glossary:
The Goal:
The goal of reinforcement learning is surprisingly intuitive:
Learn a strategy (called a policy) that helps the agent earn the most rewards over time.
In simpler terms, the agent tries different things (actions), observes the outcomes (rewards) and gradually figures out which choices lead to better results. It’s trial and error, but with purpose.
Over time, the agent improves its “gut instinct” - learning to act in ways that, on average, lead to success. Whether it’s revealing safe tiles in Minesweeper or generating accurate, helpful responses in an LLM, the objective is the same:
Maximise the total reward over a sequence of actions.
That’s the core of reinforcement learning - everything else is just figuring out how best to do that..
The RL Loop
Every RL problem plays out over time in a loop:
1). Observe the current state $s_t$
2). Choose an action $a_t$ based on the policy $\pi(a_t \mid s_t)$
3). Execute that action -> environment transitions into new state $s_{t+1}$ and gives reward $r_t$.
4). Update the policy using the experience $(s_t, a_t, r_t, s_{t+1})$
Repeat. Learn. Improve.
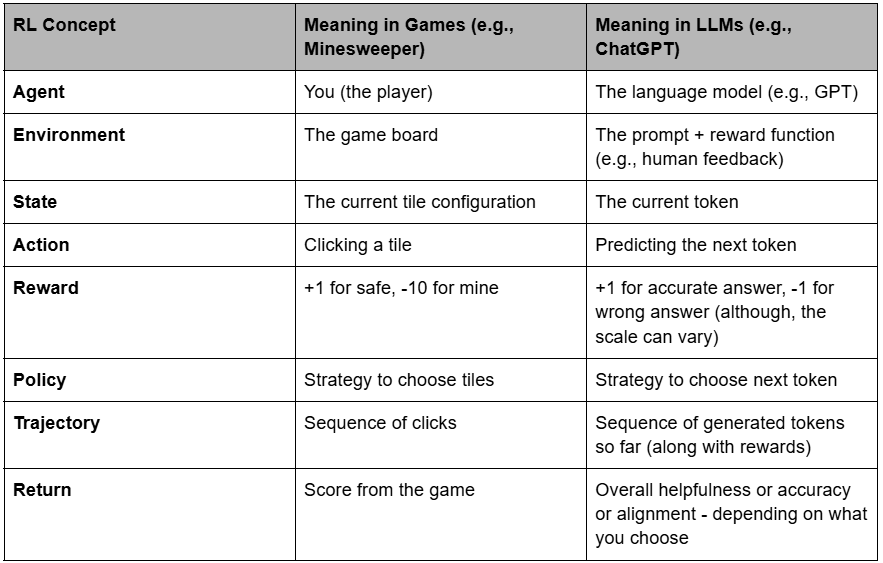
What Does RL Look Like in the Context of LLMs?
Now that we understand how reinforcement learning works in general, let’s translate this vocabulary to the world of Large Language Models (LLMs)
Wrapping Up: Where Do We Go from Here?
Now that we’ve grounded ourselves in what RL is and how it maps to both games and language models, we’re ready to zoom into the actual learning algorithms that power this behaviour. But before we throw equations into your face with gradients, Kullback-Liebler divergence and policy objectives, we hope to build your understanding in layers.
In the next chapter of this series, we’ll explore one of the most important distinctions in Reinforcement learning:
Policy-Based vs Value-Based RL
You’ll learn why this split exists, how these two schools of thought differ and where each shines (or struggles!). This will serve as a crucial fork in the road - and set us up nicely for understanding advanced algorithms like PPO, GRPO, DAPO and GSPO down the line.
Let’s take it one step at a time. See you in part 2. Until then, keep exploring! 🙂