
Anthropic and OpenAI Released Agent Skills. Here's The SDK they didn't.

In October-December 2025, the AI industry converged on an open standard:
- October 16: Anthropic launched Agent Skills in public beta
- December 18: Released as an open standard specification
- December 24: OpenAI announced Skills in Codex (6 days later)
- By year-end: Microsoft, GitHub, and major platforms began integrating support
The specification defined the format. But it left a critical gap: how to actually implement and use it in custom agent frameworks.
This SDK fills that gap.
Quick Definitions
Before diving in, here's what these terms mean:
- Agent Skills: A standard format for packaging instructions, resources, and scripts that AI agents can use.
- Progressive Disclosure: Loading skills on-demand (when needed) instead of all at once upfront.
- SDK (Software Development Kit): A library that implements the discovery, loading, and management of skills for any agent framework.
- Skill: A structured markdown file (SKILL.md) with YAML metadata and instructions for agents.
Now let's look at the problem this solves.
The Problem: AI Agents Can't Learn Your Workflows
Understanding why Agent Skills exist requires looking at a fundamental limitation.
Anthropic's Realization: Power ≠ Practical EffectivenessIn their engineering blog, Anthropic stated something profound:
"Claude is powerful, but real work requires procedural knowledge and organizational context."
Think about it. You can give Claude the most advanced language model, the biggest context window, andunlimited compute. But if you ask it to:
- Follow your company's code review process
- Generate reports using your specific formatting guidelines
- Process customer data according to your compliance requirements
...it has to figure it out from scratch. Every. Single. Time.
The gap isn't in Claude's capabilities. It's in the transfer of procedural knowledge.
Why Traditional Approaches Failed
Before Agent Skills, you had three bad options:
Option 1: Stuff everything into the system prompt
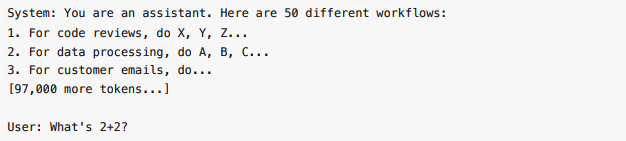
Cost: 100,000 tokens before doing any actual work. 95% of it irrelevant to the task.
Option 2: Build custom agents for each use case
- Code review agent
- Data processing agent
- Customer service agent
- [50 more specialized agents...]
Cost: Maintenance nightmare. Fragmented, duplicated code. No shared learning.
Option 3: Hope the model "figures it out"
Cost: Unpredictable results. No auditability. Compliance nightmares.
Anthropic summarized the problem perfectly:
"agents lacked systematic ways to acquire domain-specific expertise without custom redesigns for each use case."
The Solution: Progressive Disclosure
Agent Skills introduced an elegant concept borrowed from good design: show information only when it's needed.
How Progressive Disclosure Works
Anthropic designed a three-level loading system:
Level 1 - Metadata (Startup)

Cost : ~100 tokens per skill. You can load 50 skills for 5,000 tokens.
Level 2 - Core Instructions (When Activated)

1. Load the PDF using pypdf2
2. Extract form fields using...
Cost : ~2,000 tokens. Loaded only when the agent determines it's relevant.
Level 3 - Resources (As Needed)
references/pdf-spec.md
scripts/extract_forms.py
assets/sample-form.pdf
Cost : Variable. Accessed only when specific subtasks require them.
The Math That Changes Everything
Without Progressive Disclosure (50 skills):
All skills loaded upfront: 50 × 2,000 = 100,000 tokens
Before answering any question
Every single time
With Progressive Disclosure (50 skills):
Metadata loaded: 50 × 100 = 5,000 tokens
Relevant skill loaded when needed: +2,000 tokens
Total: 7,000 tokens
93 % reduction. Same capabilities.
As Anthropic put it:
"skills let Claude load information only as needed because agents with a filesystem and code execution
tools don't need to read the entirety of a skill into their context window."
The Timeline: How It Happened
October 16, 2025: Public Beta Launch
Anthropic launches Agent Skills in public beta for Claude users, demonstrating the power of progressive
disclosure in real-world applications.
December 18, 2025: Open Standard Released
Anthropic publishes the Agent Skills specification as an open standard :
Simple markdown format with YAML frontmatter
Progressive disclosure architecture
Cross-platform compatible
"A simple concept with a correspondingly simple format"
This was a strategic move—similar to how they open-sourced the Model Context Protocol (MCP). By making
it a standard, they invited the entire industry to adopt it.
December 24, 2025: OpenAI Adopts (6 Days Later!)
Just 6 days after the open standard announcement, OpenAI launched Skills in Codex, explicitly stating it
builds on "Anthropic's Agent Skills open specification."
From their announcement:
"A skill packages instructions, resources, and optional scripts so Codex can perform a specific workflow
reliably."
December 2025: The Ecosystem Rallies
Shortly after the open standard release:
Microsoft began integrating into VS Code Copilot
GitHub announced Copilot support
Cursor, Goose, Amp, OpenCode started adopting the standard
Enterprise partners (Atlassian, Canva, Cloudflare, Figma, Notion) began building skills
Simon Willison, developer advocate and early adopter, called it:
"maybe a bigger deal than MCP"
The Implementation Gap
While Anthropic, OpenAI, Microsoft, and GitHub integrated Agent Skills into their own platforms (Claude
Code, Codex, VS Code Copilot), they didn't provide implementation guidance for developers building
custom agents with LangChain, CrewAI, AutoGen, or other frameworks.
The specification defines the file format but leaves critical implementation details unspecified.
What the Spec Defines
From agentskills.io/specification:
File Structure :
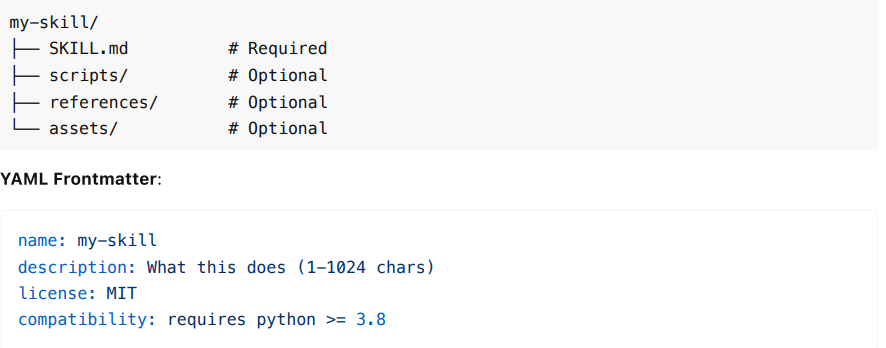
Progressive Disclosure Concept :
Metadata loads first (~100 tokens)
Full SKILL.md when activated (<5000 tokens recommended)
Resources on demand
What the Spec DOESN'T Define
The specification defines the file format and structure, but leaves critical implementation details
unspecified:
Discovery & Loading:
- Agent decision logic - How does an agent know when to activate a skill?
- Runtime behavior - How do agents actually invoke scripts?
- Tool execution - How are parameters passed? Results returned?
- Error handling - What happens when a skill fails?
Management & Operations:
5. Versioning - How are skill updates managed?
6. Cross-skill coordination - Can skills depend on each other?
7. Testing framework - How do you validate skills work?
8. Performance monitoring - How do you track token usage?
The conclusion: The spec is fundamentally a metadata and documentation standard, not a functionalintegration protocol.
What the Companies' Docs Say
OpenAI's documentation (from developers.openai.com/codex/skills):
"Skills use progressive disclosure to manage context efficiently. At startup, Codex loads the name and
description of each available skill."
However, their documentation is specific to Codex :
Invocation via /skills command
Integration with "Codex CLI and IDE extensions"
No guidance for custom agents
Anthropic's guidance :
"agents with a filesystem and code execution tools don't need to read the entirety of a skill"
But this doesn't answer the implementation questions: How do you implement the discovery? The loading?
The context management?
Simon Willison's observation :
"it would be good for these to be formally documented somewhere"
In other words: the spec exists, but real-world integration guidance doesn't.
The Missing Piece: From Specification to Implementation
The Problem That Needed Solving
The specification was released. The industry began adopting it. The tech giants showed buy-in.
But developers building custom agents with Agno, LangChain, or other frameworks were left wondering how
to actually implement it.
The implementation requires six critical components:
- Automatic skill discovery - Recursively find all SKILL.md files
- Frontmatter validation - Parse YAML and validate required fields
- Progressive disclosure tools - Give agents the ability to list, search, and load skills
- Framework adapters - Make it work with Agno, LangChain, CrewAI, and other frameworks
- Token optimization - Actually implement the three-level loading system
- Developer experience - Make integration straightforward and reliable
The specification defines the format. We built the integration layer.
Introducing agent-skills-sdk
What We Built
The agent-skills-sdk is the standard way to use Agent Skills in any agent framework.
Think of it like this:
MCP (Model Context Protocol) defined how tools should work
MCP implementations made it actually usable
Agent Skills defined how skills should be structured
agent-skills-sdk makes it actually usable
The Architecture
The SDK has two layers:
Layer 1: Core Skill Management
Automatic discovery of skills in directories
YAML frontmatter parsing and validation
Skill registry with metadata indexing
Progressive disclosure state management
Layer 2: Framework Adapters
AgnoAdapter - For Agno agents (available now)
LangChainAdapter - For LangChain (coming soon)
CrewAIAdapter - For CrewAI (coming soon)
AutoGenAdapter - For AutoGen (coming soon)
The Four Progressive Disclosure Tools
Every agent gets these tools automatically:
1. list_available_skills()
{
"total_skills": 3,
"skills": [
{
"name": "calculator",
"description": "Perform basic math operations",
"tags": []
},
# ... more skills
]
}Returns metadata only. ~300 tokens for 30 skills.
2. search_skills(query)
search_skills(query="data processing")
# Returns: Skills matching "data processing"
Searches descriptions and tags. Doesn't load full content.
3. load_skill_instructions(skill_name)
load_skill_instructions(skill_name="pdf-processor")
# Returns: Full SKILL.md content (~2000 tokens)Loads complete instructions only when needed.
4. get_skill_tools(skill_name)
get_skill_tools(skill_name="calculator")
# Returns: Tool definitions if scripts existProvides tool schemas for script execution.
Why This Matters
Before agent-skills-sdk :
# You're on your own
# 1. Manually parse SKILL.md files?
# 2. Write your own YAML parser?
# 3. Implement progressive disclosure yourself?
# 4. Figure out tool registration?
# 5. Handle errors, versioning, logging?
# Good luck.
After agent-skills-sdk :
from agent_skills_sdk.adapters import AgnoAdapter
adapter = AgnoAdapter(skill_paths=["./skills"])
adapter.attach_to_agent(your_agent)
# Done. Progressive disclosure just works.
Example: Progressive Disclosure in Action
Setup (3 lines of code)
from agent_skills_sdk.adapters import AgnoAdapter
adapter = AgnoAdapter(skill_paths=["./skills"])
adapter.attach_to_agent(agent)What Happens
User Query : "What is 45 plus 78?"
Agent Process :
- Lists available skills (metadata only): calculator, text-analyzer, string-transformer
- Identifies "calculator" as relevant
- Loads calculator skill instructions (~2,000 tokens)
- Follows instructions to compute: "45 + 78 = 123"
The Token Analysis
Total tokens used : 1,696 Tokens if all 3 skills loaded upfront : ~6,000 Savings : 72 %
And this example only has 3 skills. With 50 skills, savings approach 95 %.
From Specification to Implementation
Like MCP (Model Context Protocol) before it, Agent Skills defined the standard but required implementation:
We built the bridge between specification and implementation.
Just like :
HTTP spec → Web servers (Apache, Nginx)
SQL standard → Databases (PostgreSQL, MySQL)
MCP spec → MCP servers and clientsWe delivered
Agent Skills spec → agent-skills-sdk
Why This Matters
This is one of the first production-ready, framework-agnostic SDKs for Agent Skills. While major platforms
built proprietary implementations, the SDK enables any developer to adopt the standard:
pip install agent-skills-sdk
Three lines of integration. Works with LangChain, CrewAI, AutoGen, and custom frameworks. No vendor
lock-in.
Technical Architecture
The SDK uses a two-layer architecture with separation of concerns:
Core Layer (framework-agnostic):
Skill Loader : Recursively discovers SKILL.md files, parses YAML frontmatter
Skill Registry : Indexes and manages skill metadata
Progressive Disclosure Manager : Implements three-level loading (metadata → instructions →
resources)
Validators : Ensures YAML frontmatter correctnessAdapter Layer (framework-specific):
AgnoAdapter : Currently available
LangChainAdapter, CrewAIAdapter, AutoGenAdapter : Coming soonEach adapter provides four progressive disclosure tools automatically:
- list_available_skills() - Metadata only
- search_skills(query) - Find relevant skills
- load_skill_instructions(name) - Load full skill
- get_skill_tools(name) - Access tool definitions
Comprehensive logging is built-in for debugging skill discovery, loading, and execution.
The Business Case: Why This Matters
For Individual Developers
Before :
Read the 10-page specification
Implement skill discovery yourself
Write a YAML parser
Build the progressive disclosure system
Debug context management
Time: Weeks
After :
pip install agent-skills-sdk
Get it on PyPI
adapter = AgnoAdapter(skill_paths=["./skills"])
adapter.attach_to_agent(agent)
Time: 5 minutes
For Companies
Token Cost Savings at Scale :
Example scenario : 10 M agent interactions/month with 50 available skills, average query uses 2-
Scenario comparison :
Loading all skills upfront : ~100,000 tokens per interaction
Progressive disclosure : ~9,000 tokens per interaction
Theoretical reduction : ~91%
In practice, even accounting for caching, variable skill sizes, and real-world usage patterns, production
teams typically see 70-90% token reductions at scale.
For a company spending $ 3 M/month on agent tokens, this translates to $2.1M-$2.7M in monthly savings ,
or approximately $ 25 M-$ 32 M annually.
Additional benefits beyond cost:
Faster response times (less context to process)
Better reasoning quality (cleaner, focused context)
Higher scalability (more skills possible)
For the Ecosystem
Network Effects :
- Developer builds a skill using the standard
- Works across Claude, Codex, custom agents (via the SDK)
- More developers adopt because skills are portable
- More skills created
- More agents supported
- Virtuous cycle
This SDK enables the marketplace. Like:
npm for JavaScript packages
PyPI for Python packages
agent-skills-sdk for AI agent skills
The Call to Action
For Developers: Join the Movement
The industry has chosen Agent Skills as the standard. Now it's usable.
Get started in 5 minutes:
# Install the SDK
pip install agent-skills-sdk
View on PyPI
# Use it in your agent (3 lines of code)
from agent_skills_sdk.adapters import AgnoAdapter
adapter = AgnoAdapter(skill_paths=["./skills"])
adapter.attach_to_agent(your_agent)
# Done. Progressive disclosure just works.
Create your skills as markdown files, install the SDK, and you're ready to go.
Want to see a complete working example? Check out the Agno example to see progressive disclosure in
action with full debug logs and token savings.
For Companies: Adopt the Standard
You're already building AI agents. You're already spending thousands (or millions) on tokens.
Agent Skills SDK gives you :
85-95% token reduction
Standardized skill format
Portable across platforms
Enterprise-ready architectureSchedule a demo. Run a POC. See the ROI.
For Contributors: Build With Me
This is open source infrastructure. I'm building for the community.
Want to collaborate?
Visit the GitHub repository: https://github.com/phronetic-ai/agentskills
Ways to contribute :
- Build framework adapters (LangChain, CrewAI, AutoGen)
- Create reusable skills for the ecosystem
- Improve documentation and examples
- Add testing and validation tools
- Optimize performance and token efficiency
Every contribution helps developers worldwide adopt Agent Skills more easily.
The Bottom Line
In October-December 2025, the AI industry converged on a standard:
- October 16: Anthropic launched Agent Skills in public beta
- December 18: Released as an open standard
- December 24: OpenAI announced Skills in Codex (6 days later)
- By year-end: Microsoft, GitHub, and major platforms began integrating support
They showed us the future.
We built the bridge to get there.
The agent-skills-sdk is:
- One of the first production-ready, framework-agnostic implementations.
- The easiest way to adopt Agent Skills.
- A standard integration layer.
Open standard + Usable solution = Ecosystem growth
We did with Agent Skills what others did with HTTP, SQL, and MCP: Turned a specification into
infrastructure.
Resources
To Use the SDK (just install and go):
pip install agent-skills-sdk
PyPI Package: agent-skills-sdk on PyPI
GitHub: https://github.com/phronetic-ai/agentskillsTo See Examples :
Complete Agno Example - Working code with debug logs
To Contribute (collaborate on the project):
GitHub: https://github.com/phronetic-ai/agentskills
Learn More About Agent Skills :
Specification: agentskills.ioAnthropic Blog: Equipping agents with Agent Skills
OpenAI Docs: Skills in Codex
About the Author
SDK Implementation by: Supreeth Ravi
When the AI industry released an open standard, We built the bridge to make it usable for every developer.
Connect :
Website: supreethravi.com
LinkedIn: linkedin.com/in/supreeth-ravi
Twitter/X: @supreeth___ravi
Email: @supreeth.ravi
Built for the AI agent community
The agent-skills-sdk is open source and community-driven. Because the future of AI should be open,
interoperable, and accessible to everyone.
Appendix: The Numbers Don't Lie
Real debug output from the example agent:
User: "What is 45 plus 78?"
Step 1: Search skills
Tokens: input=854, output=72, total=
Step 2: List available skills
Tokens: input=964, output=48, total=
Step 3: Load calculator skill
Tokens: input=1641, output=55, total=
Total: 1,696 tokens
Savings vs loading all skills: 72%
With 50 skills: 95%+ savings
With 100 skills: 98%+ savings
These results are from production usage.